This manual is intended as a guide to users of nuclear reaction data compiled in the EXFOR format, and is not intended as a complete guide to the EXFOR System.
EXFOR is the exchange format designed to allow transmission of nuclear reaction data between the Nuclear Reaction Data Centers. In addition to storing the data and its' bibliographic information, experimental information is also compiled. The status (e.g., the source of the data) and history (e.g., date of last update) of the data set is also included.
EXFOR is designed for flexibility in order to meet the diverse needs of the nuclear reaction data centers. It was originally conceived for the exchange of neutron data and was developed through discussions among personnel from centers situated in Saclay, Vienna, Livermore and Brookhaven. It was accepted as the official exchange format of the neutron data centers at Saclay, Vienna, Brookhaven and Obninsk, at a meeting held in November 1969. As a result of two meetings held in 1975 and 1976 and attended by several charged-particle data centers, the format was further developed and adapted to cover all nuclear reaction data.
The exchange format should not be confused with a center-to-user format. Although users may obtain data from the centers in the EXFOR format, other center-to-user formats have been developed to meet the needs of the users within each center's own sphere of responsibility.
The EXFOR format, as outlined, allows a large variety of numerical data tables with explanatory and bibliographic information to be transmitted in a format:
The data presently included in the EXFOR exchange file include:
An exchange file contains a number of entries (works). Each entry is divided into a number of subentries (data sets). Each entry is assigned an accession number; each subentry is assigned a subaccession number (the accession number plus a subentry number). The subaccession numbers are associated with a data table throughout the life of the EXFOR system.
The subentries are further divided into:
The file may, therefore, be considered to be of the following form:
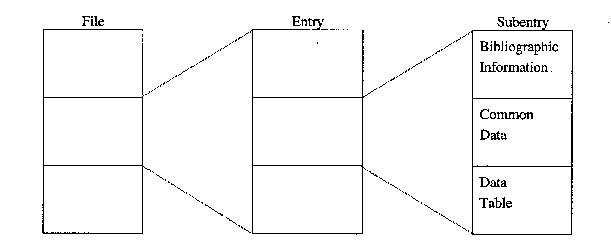
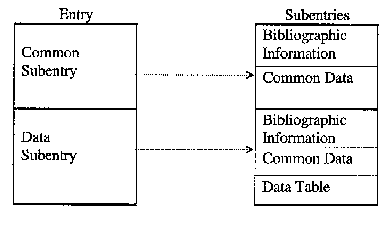
In order to avoid repetition of information that is common to all subentries within an entry or to all lines within a subentry, information may be associated with an entire entry or with an entire subentry. To accomplish this, the first subentry of each work contains only information that applies to all other subentries. Within each subentry, the information common to all lines of the table precedes the table. Two levels of hierarchy are thereby established:
The following characters are permitted for use in the exchange format:
| All Roman characters: A to Z and a to z | All numbers: 0 to 9 | |||
| The following special characters: | ||||
| + | (plus) | > | (greater than) | |
| - | (minus) | : | (colon) | |
| . | (decimal point/full stop) | ; | (semi-colon) | |
| ) | (right parenthesis) | ! | (exclamation mark) | |
| ( | (left parenthesis) | ? | (question mark) | |
| * | (asterisk) | & | (ampersand) | |
| / | (slash) | # | (number symbol) | |
| = | (equals) | [ | (opening bracket) | |
| ' | (apostrophe) | ] | (closing bracket) | |
| , | (comma) | " | (quotation mark) | |
| % | (percent) | ~ | (varies as sign) | |
| < | (less than) | @ | (at symbol) | |
EXFOR Exchange files consist of 80 character ASCII records. The format of columns 1-66 varies according to the record type as outlined in the following chapters. Columns 67-79 is used to uniquely identify a record within the file. The records on the file are in ascending order according to the record identification. Column 80 is reserved for an alteration flag.
The record identification is divided into three fields: the accession number (entry), subaccession number (subentry), and record number within the subentry. The format of these fields is as follows.
| Columns | 67-71 | Center-assigned accession number |
| 72-74 | Subaccession number | |
| 75-79 | Sequence number |
The last column of each record contains the alteration flag which is used to indicate that a record and/or following records has been altered (i.e., added, deleted or modified) since the work was last transmitted. The flag field will normally contain a blank to indicate an unaltered record.
Each of the sections of an EXFOR file begins and ends with a system identifier. Each of the following system identifiers indicates the beginning of one of these sections.
| trans | - A file is the unit |
| entry | - An entry is the unit |
| subent | - A subentry is the unit |
| bib | - A BIB Information section is the unit |
| common | - A common data section is the unit |
| data | - A data table section is the unit |
The following system identifiers are defined.
Different pieces of EXFOR information may be linked together by pointers. A pointer is a numeric or alphabetic character (1,2...9,A,B,...Z) placed in the eleventh column of the information-identifier keyword field in the BIB section and in the field headings in the COMMON or DATA section.
Pointers may link, for example,
In general, a pointer is valid for only one subentry. A pointer used in the first subentry applies to all subentries and has a unique meaning throughout the entire entry.
The BIB section contains the bibliographic information (e.g., reference, authors), descriptive information (e.g., neutron source, method, facility), and administrative information (e.g., history) associated with the data presented. It is identified on an exchange file as that information between the system identifiers bib and endbib.
A BIB record consists of three parts:
| Columns 1-11: | information-identifier keyword field, |
| Columns 12-66: | information field, which may contain coded information and/or free text, |
| Columns 67-80: | record identification and alteration flag fields. |
BIB information for a given data set consists of the information contained in the BIB section of its subentry together with the BIB information in subentry 001. That is, information coded in subentry 001 applies to all other subentries in the same entry. A specific information-identifier keyword may be included in either subentry or both.
The information-identifier keyword is used to define the significance of the information given in columns 12-66. The keyword is left adjusted to begin in column 1, and does not exceed a length of 10 characters (column 11 is either blank, or contains a pointer).
These keywords may, in general, appear in any order within the BIB section, however, an information-identifier keyword is not repeated within any one BIB section. If pointers are present, they appear on the first record of the information to which they are attached and are not repeated on continuation records. A pointer is assumed to refer to all BIB information until either another pointer or a new keyword is encountered. As this implies, pointer-independent information for each keyword appears first.
Coded information may be used:
Coded information is enclosed in parentheses and left adjusted so that the opening parenthesis appears in column 12. Several pieces of coded information may be associated with a given information-identifier keyword.
Codes for use with a specific keyword are found in the relevant dictionary. However, for some keywords, the code string may include retrievable information other than a code from one of the dictionaries.
In general, codes given in the dictionaries may be used singly or in conjunction with one or more codes from the same dictionary. Two options exist if more than one code is used:
For some cases, the information may be continued onto successive records. Information on continuation records does not begin before column 12 (columns 1-10 are blank and column 11 is blank or contains a pointer).
Note that some information-identifier keywords have no coded information associated with them and that, for many keywords which may have coded information associated with them, it need not always be present.
Free text may be entered in columns 12-66 under each of the information-identifier keywords in the BIB section. The text follows any coded information on the record or may begin on a separate record; it may be continued onto any number of records.
The language of the free text is English.
Nuclides appear in the coding of many keywords. The general code format is Z-S-A-X, where:
Examples: 92-U-235, 49-IN-115-M/T
Compounds may in some cases replace the nuclide code. The general format for coding compounds is either the specific compound code, taken from Dictionary 9, or the general code for a compound of the form Z-S-CMP.
Example: 26-FE-CMP
A data table is, generally, a function of one or more independent variables, e.g.,
When more than one representation of Y is present, the table may be X vs. Y and Y' , with associated errors for X, Y and Y' (e.g., X = energy, Y = absolute cross section, Y' = relative cross section), and possible associated information. The criteria for grouping Y with Y' are that they both be derived from the same experimental information by the author of the data.
For some data, the data table does not have an independent variable X but only a function Y. (Examples: Spontaneous` n nubar; resonance energies without resonance parameters)
Additional variables may be associated with the data, e.g., errors, standards.
The format of the common data (COMMON) and data table (DATA) sections is identical. Each section is a table of data containing the data headings and units associated with each field. The difference between the common data and data table is:
Each physical record may contain up to six information fields, each 11 columns wide. If more than six fields are used, the remaining information is contained on the following records. Therefore, a data line consists of up to three physical records. The number of fields in a data line is restricted to 18.
Records are not packed; rather, individual point information is kept on individual records; i.e., if only four fields are associated with a data line, the remaining two fields are left blank, and, in the case of the data table, the information for the next line begins on the following record. These rules also apply to the headings and units associated with each field.
The content of the COMMON and DATA sections are as follows:
The values are either zero or have absolute values between 1.0000E-38 and 9.999E+38.
The COMMON section is identified as that information between the system identifiers COMMON and ENDCOMMON. In the common data table, only one value is entered for a given field, and successive fields are not integrally associated with one another.
An example of a common data table with more than 6 fields:
1 12 23 34 45 56 66
COMMON
EN EN-ERR EN-RSL E-LVL E-LVL MONIT
MONIT-ERR
MEV MEV MEV MEV MEV MB
MB
2.73 0.02 0.05 2.73 2.78 3.456
0.123
ENDCOMMON
The DATA section is identified as that information between the system identifiers DATA and ENDDATA. In the DATA table, all entries on a record are integrally associated with an individual point. Independent variables precede dependent variables, and are monotonic until the value of the preceding independent variable, if any exist, changes.
Every line in a data table gives data information. This means, for example, that a blank in a field headed DATA is permitted only when another field contains the data information on the same line, e.g., under DATA-MAX. In the same way, each independent variable occurs at least once in each line (e.g., either under data headings E-LVL or E-LVL-MIN, E-LVL-MAX, see example following). Supplementary information, such as resolution or standard values, is not given on a line of a data table unless the line includes data information. Blanks are permitted in all fields.
An example of a point data table is shown below with its associated data and enddata records.
1 12 23 34 45 56 66
DATA
ANG ANG-ERR DATA DATA-ERR DATA-MAX
ADEG ADEG MB/SR MB/SR MB/SR
10.7 1.8 138. 8.5
22.9 1.2 127. 4.2
39.1 0.9 83.2
46.7 0.7 14.8 2.9
ENDDATA
This work was performed under the auspices of the U. S. Department of Energy, Division of Nuclear Physics, Office of Science.
The author would like to thank the members of the Nuclear Reaction Data Center Network, especially, H. D. Lemmel and O. Schwerer of the International Atomic Energy Agency Nuclear Data Section, and S. Maev of the Russian Nuclear Data Center for their contributions.
This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, nor any of their contractors, subcontractors, or their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency, contractor, or subcontractor thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency, contractor, or subcontractor thereof.








